
Projects
AlphaDraughts Zero
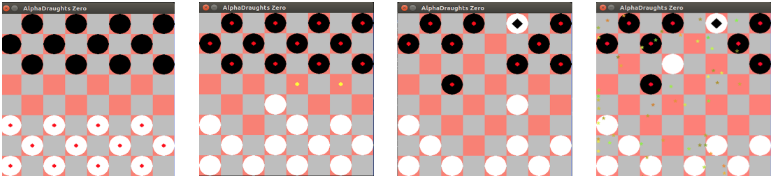
AlphaGo Zero is a historical breakthrough in Game AI, not only because that it beated all the previous versions and all human experts, but also because that it is learnt by self-play without any human knowledge.
In this project, we investigate at first the algorithm flow of AlphaGo Zero. A readily compmrehensible interpretation is provided. We then apply the algorithm in English Draughts.
Ensemble-Pytorch
[Code]
![]()
Ensemble-PyTorch is an open source project and is part of the PyTorch ecosystem. It provides a unified ensemble framework for PyTorch to easily improve the performance and robustness of deep learning model. I contributed to the implementation and debugging of Bagging ensemble algorithm.
OmniPrint

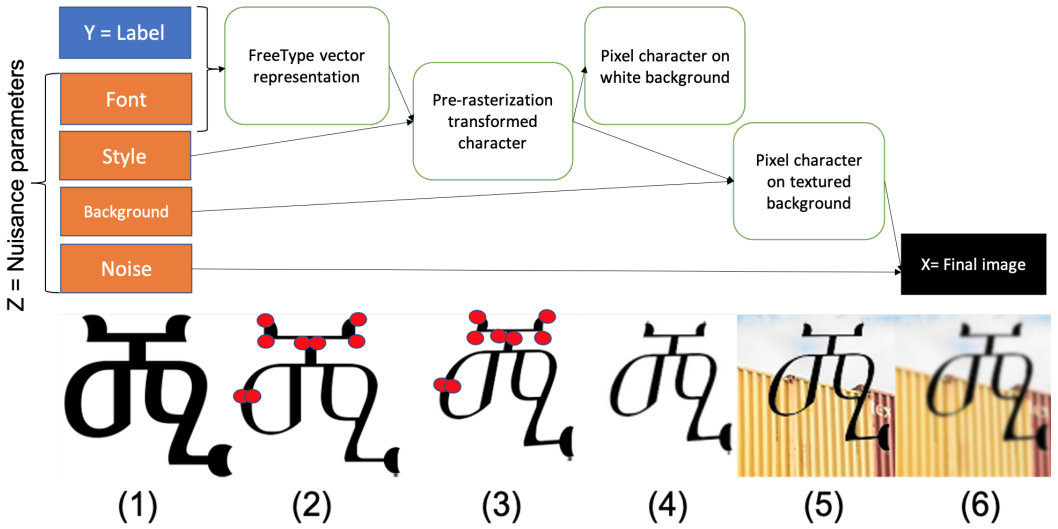
One of the most popular machine learning benchmarks is MNIST, which is used all over the world in tutorials, textbooks, and classes. Many variants of MNIST have been created, including Omniglot which includes characters from many different scripts in the world. Character images provide excellent benchmarks for machine learning problems because of their relative simplicity, their visual nature, while opening the door to high-impact real-life applications. However, collecting and labeling data is time consuming and expensive, systematically varying environment conditions is difficult and necessarily limited. Therefore, resorting to artificially generated data is useful to investigate the influence of systematic variations in data.
To retain the value of a simple visual benchmark while increasing task complexity, we introduce OmniPrint. OmniPrint is a synthetic data generator1 of isolated printed characters, geared toward machine learning research. It draws inspiration from famous datasets such as MNIST, SVHN and Omniglot, but offers the capability of generating a wide variety of printed characters from various languages, fonts and styles, with customized distortions. We include 935 fonts from 27 scripts and many types of distortions. In some respects, OmniPrint goes beyond state-of-the-art software to generate realistic characters. In particular it has the unique capability of incorporating pre-rasterization transformations, allowing users to distort characters by moving anchor points in the original font vector representation.
Copy-Move detection based on PatchMatch
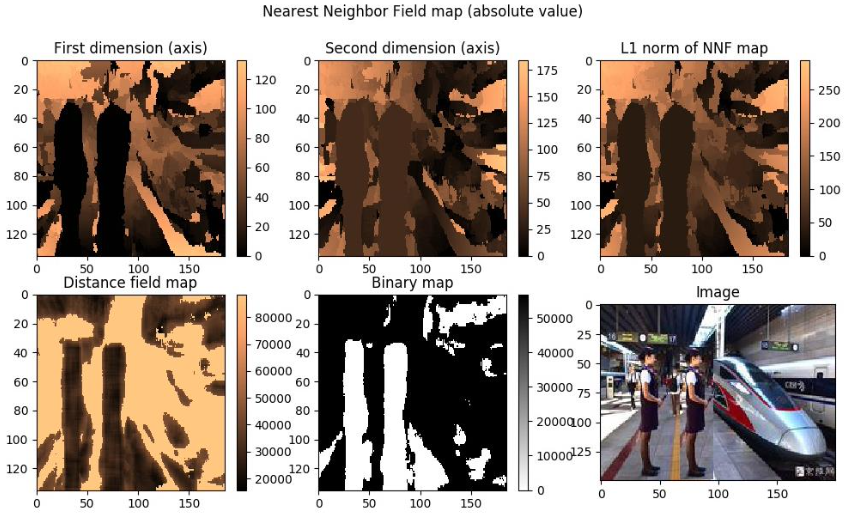
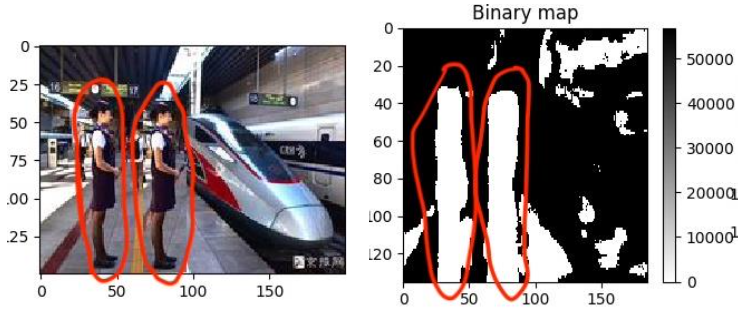
Image forensics, i.e. image edition forgery detection, is of great importance for many real life scenarios. Copy-Move forgery is a special case of image forgery. Copy-move forgery detection based on Patchmatch presented an algorithm adapted from the classical PatchMatch algorithm, aiming to increase the robustness. I have implemented this algorithm from scratch.
Kernel methods for DNA sequence prediction
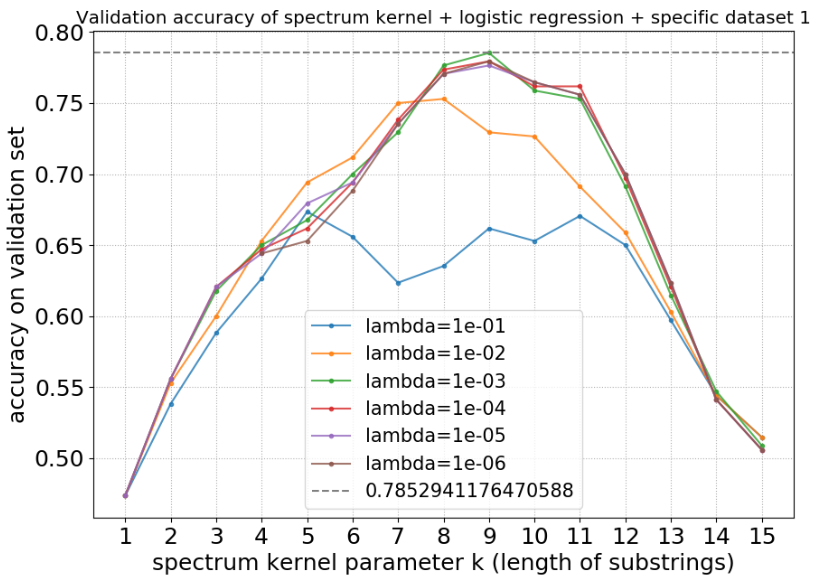
The goal of this project is to predict whether a DNA sequence region is binding site to a specific transcription factor (TF). First, I made experiments by assuming the uniform hypothesis that these 3 different TFs can be treated equally. However, the experiments showed that this hypothesis does not turn to be valid, I got better results by assuming the specific hypothesis that different TFs correspond to different distributions of DNA sequences. I implemented a general scalable framework for machine learning algorithms using kernel methods from scratch. The implemented algorithms include kernel logistic regression, kernel SVM classifier and kernel 2-SVM classifier, applied to spectrum kernel and Local Alignment (LA) kernel. These kernels can also be added up to combine multiple kernels. Then, ensemble techniques are used to improve the predictions.
Rendering and modeling of 3D objects
[Code]
Computer graphics project.
Restaurant ordering interface
[Code]
Prototype for an ordering system of restaurants in the context of a human–Computer Interaction team project.
Speech command recognition
[Report]

Classification of speech commands based on MFCC features, neural networks and beam search.
Prediction of returns of orders for a retail shoe seller
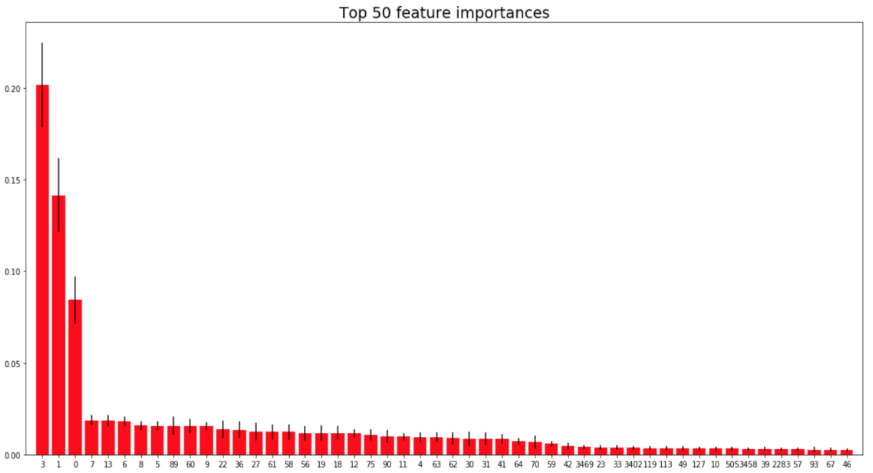
In this project, I trained machine learning models (XGBoost, Random Forests, etc.) to predict whether the shoes purchased will be returned by the customer. The classification features include the retail shoe seller’s database of orders placed between October 2011 and October 2015, its product feedback data, and its customer and product databases. This project is proposed by BearingPoint.
history2reality
[Code]


CycleGAN, one instance of generative model, allows training of image-to-image translation models without paired examples. One task we proposed is to generate realistic portraits from historical paintings, for example, generating a realistic portrait of Napolon Bonaparte based on one of his paintings. One of the challenges is the lack of data, which requires building a new dataset and the preprocessing of data to allow a convergence of model and a reasonable result of the experiment. For this purpose, we built a dataset consisting of realistic portraits and historical painting to train CycleGAN.
Huawei Big Data Challenge Hackathon France 2018
Dynamic malware detection based on the process generation tree of the software and its sequences of behaviors (Process, RIP, API) recorded in the order of time.