nvidia-smi
NVIDIA System Management Interface (nvidia-smi)
1 | |
Test whether GPU is being used
directly test with PyTorch
1 | |
with nvidia-smi
With nvidia-smi can check whether Memory-Usage is (always) 0MiB / XXXXXMiB, whether Volatile GPU-Util is (always) 0%. In the bottom, there is the Processes section, one can check whether there is our process, or whether it is No running processes found.
gpustat
https://github.com/wookayin/gpustat
In order to install the python package gpustat
1 | |
To use gpustat
1 | |
Default display (in each row) contains:
- GPUindex (starts from 0) as PCI_BUS_ID
- GPU name
- Temperature
- Utilization (percentage)
- GPU Memory Usage
- Running processes on GPU (and their memory usage)
nvcc
The following command may not be found in docker (it is only available in versions with tag devel )
1 | |
Docker
1 | |
Questions
- Running more than one CUDA applications on one GPU
https://stackoverflow.com/questions/31643570/running-more-than-one-cuda-applications-on-one-gpu
CUDA activity from independent host processes will normally create independent CUDA contexts, one for each process. Thus, the CUDA activity launched from separate host processes will take place in separate CUDA contexts, on the same device. CUDA activity in separate contexts will be serialized. The GPU will execute the activity from one process, and when that activity is idle, it can and will context-switch to another context to complete the CUDA activity launched from the other process. The detailed inter-context scheduling behavior is not specified.
It seems that at any given instant in time, code from only one context can run. The “exception” to this case (serialization of GPU activity from independent host processes) would be the CUDA Multi-Process Server.
Troubleshooting
Rebooting can solve some problems: sudo reboot, then enter the sudo password
- RuntimeError: CUDA error: CUBLAS_STATUS_NOT_INITIALIZED when calling
cublasCreate(handle)/opt/conda/conda-bld/pytorch_1616554793803/work/aten/src/THCUNN/ClassNLLCriterion.cu:108: cunn_ClassNLLCriterion_updateOutput_kernel: block: [0,0,0], thread: [0,0,0] Assertiont >= 0 && t < n_classesfailed.
This possibly means that there is an IndexError: Target XXX is out of bounds. error.
torch.cuda.is_available()returnsFalseandUserWarning: CUDA initialization: Unexpected error from cudaGetDeviceCount(). Did you run some cuda functions before calling NumCudaDevices() that might have already set an error? Error 804: forward compatibility was attempted on non supported HW (Triggered internally at /opt/conda/conda-bld/pytorch_1616554793803/work/c10/cuda/CUDAFunctions.cpp:109.) return torch._C._cuda_getDeviceCount() > 0
This problem is not solved.
Common GPUs
Tesla V100 is the fastest NVIDIA GPU available on the market (however, A100 seems to be even faster than V100). V100 is 3x faster than P100.
FP64 64-bit (Double Precision) Floating Point Calculations:
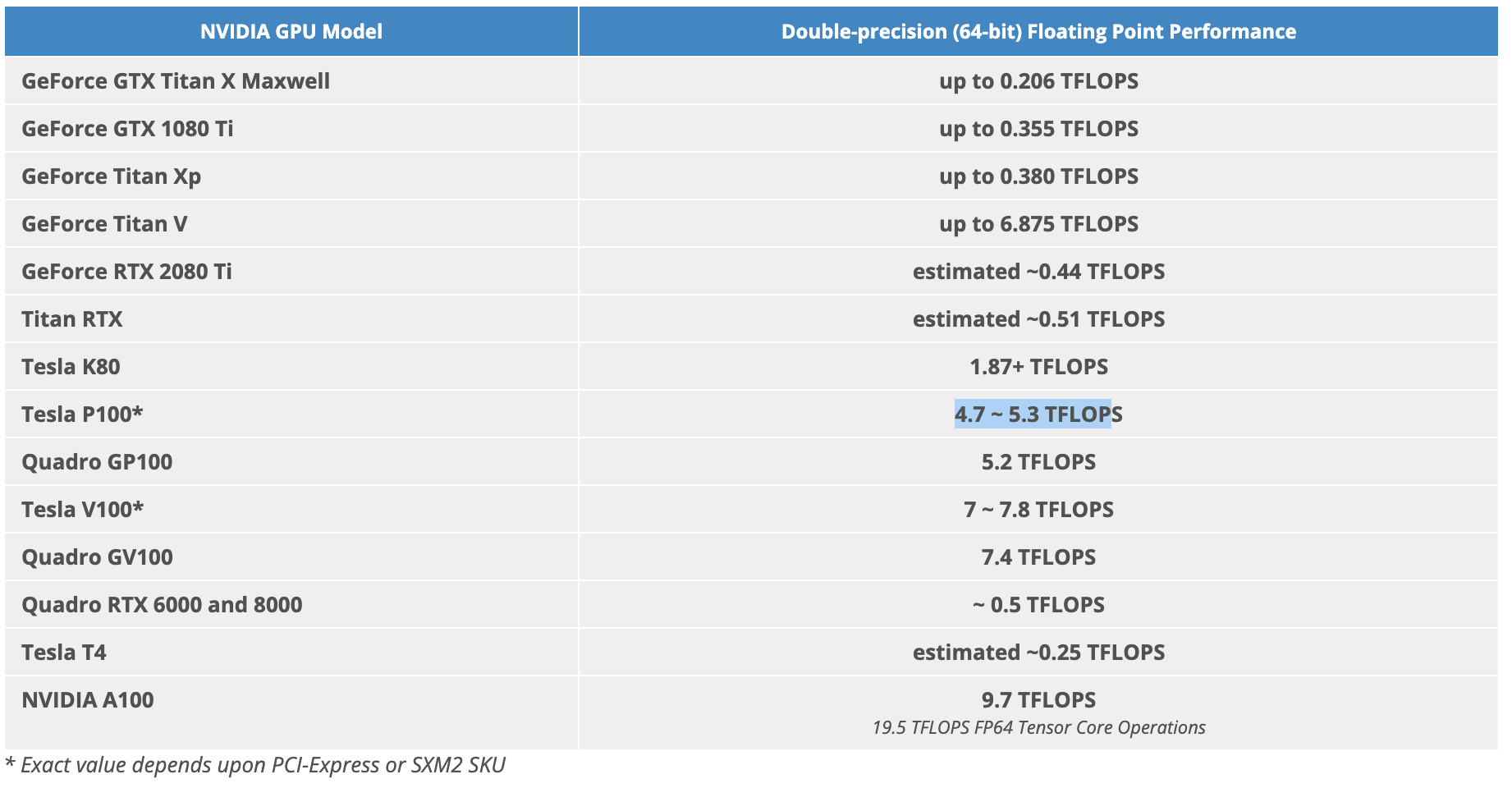
FP16 16-bit (Half Precision) Floating Point Calculations:
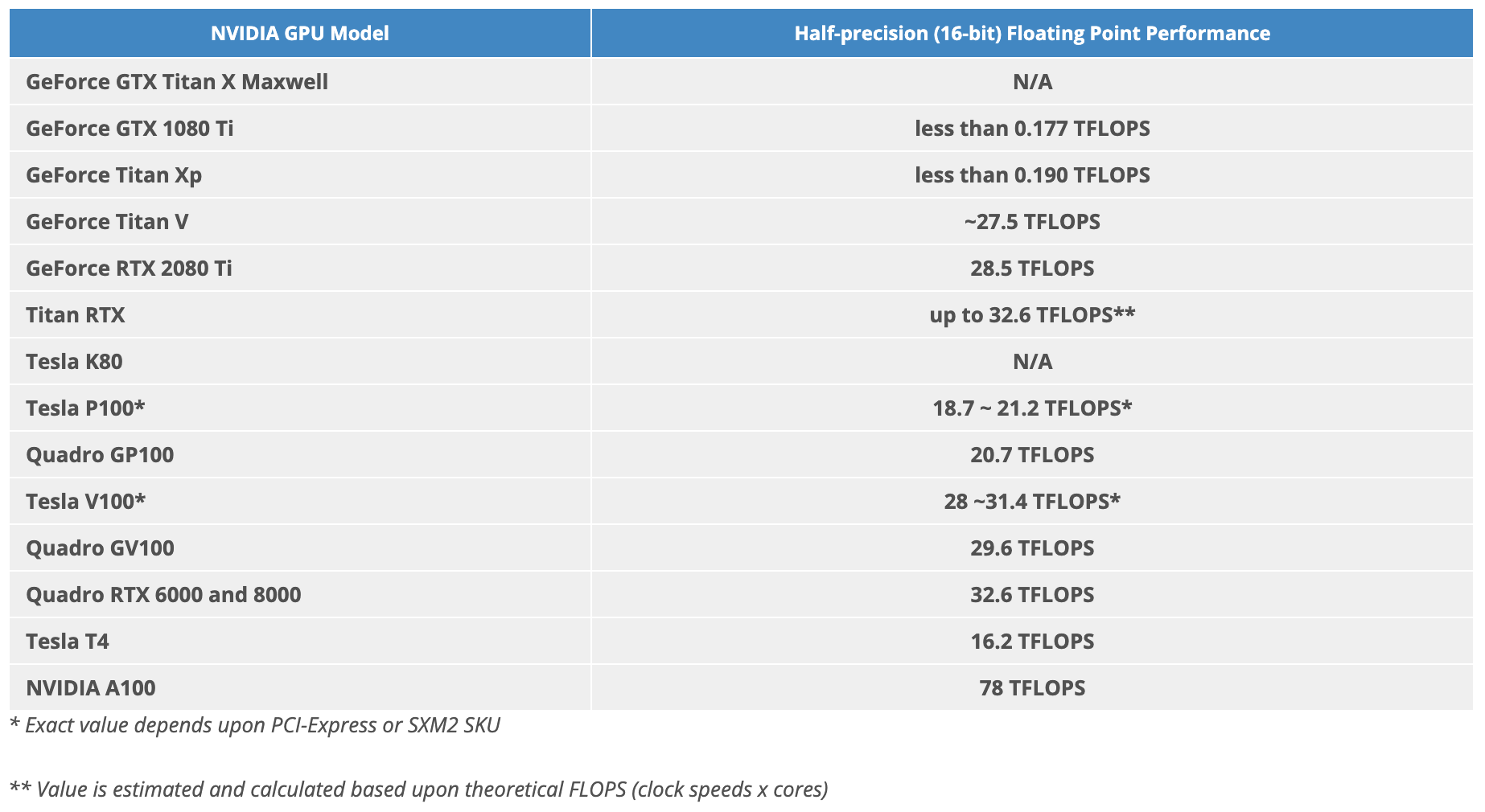
GPU Memory Quantity:
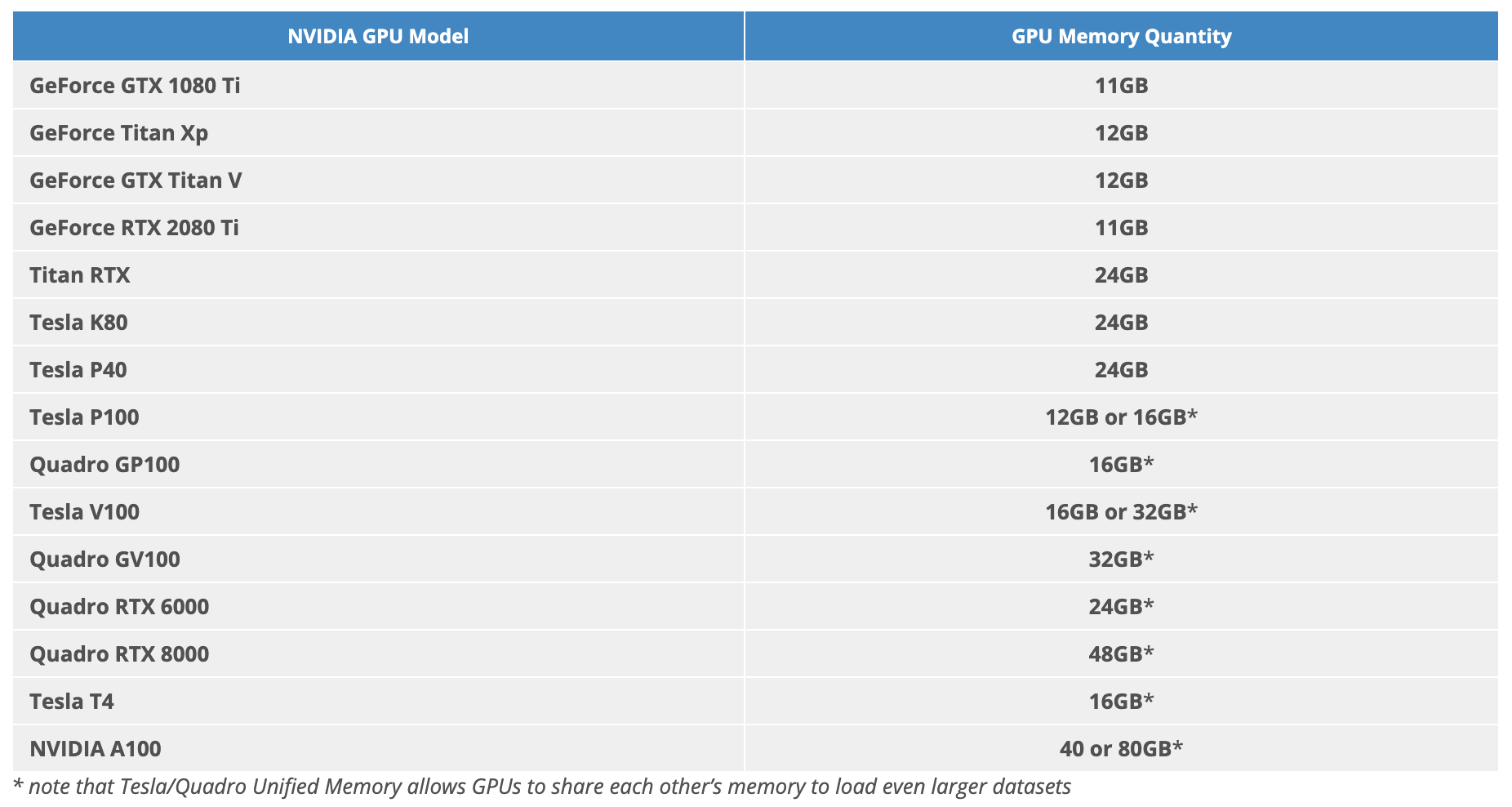
Estimated price on Google Cloud Platform:
- Tesla T4: $0.28 hourly
- Tesla K80: $0.35 hourly
- Tesla P4: $0.45 hourly
- Tesla P100: $1.06 hourly
- Tesla V100: $1.77 hourly
- Tesla A100: $2.79 hourly
GPU memory:
- GeForce RTX 2080 Ti: 11 GB
- Tesla T4: 16 GB
- K80: 24 GB
- Tesla P4: 8 GB
- P100: 12 GB or 16 GB
- V100: 16 or 32 GB
- A100: 40 GB or 80 GB